
こんにちは、知財実務情報Lab. 専門家チームの田中 研二(弁理士)です。
今回は、体系的な研究を実施する際のデータの集め方について、私なりのやり方を整理してみます。
以下、裁判例を収集する場合と、審査事例を収集する場合とに分けて説明します。
角渕先生のセミナーはいつも大人気なんですが、受講して下さった方から、
「誰でも、これだけ押さえておけば何とかなる、というセミナーはないですか?」
「基礎的なところをキッチリと固めるセミナーはないですか?」
「専用の調査データベースは使えないんですが、何とかする方法はありますか?」
「生成AIを正しく活用して調査を効率化する方法を教えて欲しいです!」
というようなご要望を頂きましたので、角渕先生にそれに応えるべく、昨年のセミナーを大幅にアップデートして頂きました!
特許の調査に携わっている方は、ぜひ、2026/4/24(金)の午後の時間を確保してセミナーにご参加ください。
詳細は以下をクリックして開くページからご確認ください。

1.裁判例の集め方
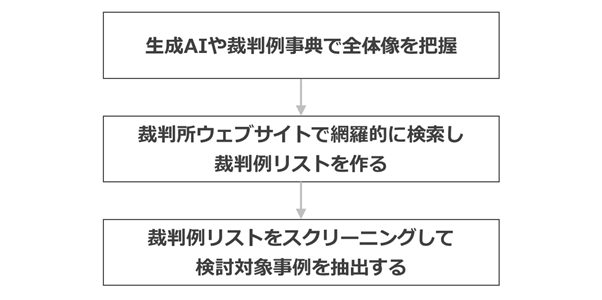
(1)生成AI
入口としては、まず生成AIに代表的な裁判例を整理させるのがかなり有効です。
たとえば、
●●に関する裁判例を網羅的に収集して、争点ごとに原告の主張・被告の主張・裁判所の判断をリスト化してください。
といった指示をすると、少なくともインターネットに解説記事が載っている裁判例については、一通りまとめてくれることが多いです。
もちろん、これだけでは網羅的調査にはなりませんが、どんな事件があるのか、どんな争点が多いのか、どの事件が重要そうか、といった概要を把握するにはかなり便利です。
(2)「論点別 特許裁判例事典 第四版」
高石秀樹先生の「論点別 特許裁判例事典 第四版」は生成AIの学習が許可されているので、NotebookLMに読み込ませて質問するのも非常に有効です。
たとえば、
「除くクレームに関する裁判例をすべて挙げてください。」
「進歩性判断において技術的意義が問題となった裁判例を整理してください。」
「明確性に関する裁判例のうち、用語解釈が争点になったものをまとめてください。」
といった質問をして、ひとまず抽出された関連裁判例に目を通しておけば、その後の調査の方針が非常に立てやすくなります。
(3)母集団の取得→スクリーニング
体系的な研究を想定している場合は、上記(1)(2)などで当たりを付けた後、裁判所の裁判例検索ページで裁判例を検索して裁判例リストを作り、そこから対象事例をスクリーニングするという段階を踏むことが多いです。
たとえば前々回の記事で挙げた「ネットワーク関連発明の侵害訴訟で充足論が判断された裁判例」の場合、まず研究対象期間の特許権侵害訴訟の裁判例リストを作成し、(i)ネットワーク関連発明であり、かつ(ii)充足論が判断されたものだけをスクリーニングすることが考えられます。
ちなみに、検索時には、研究の再現性を確保するために、検索条件と検索日をちゃんと記録しておくことが重要です。個人的には、検索画面のスクリーンショットを日付が入る形で残しておくのがオススメです。
2.審査事例の集め方
(1)生成AIでの抽出は困難?
審査事例については、現時点では、生成AIを用いた事例収集は難しいと思います。
生成AIがJPOの審査経過を閲覧できていなさそうですし、審査事例は裁判例と違って件数が膨大であり、かつウェブ上での個々の審査事例についての解説記事も乏しいためです。
(2)母集団の取得→スクリーニング
したがって、審査事例を体系的に研究するのであれば、「まず母集団を作り、スクリーニングで対象事例を抽出する」という流れが基本になります。
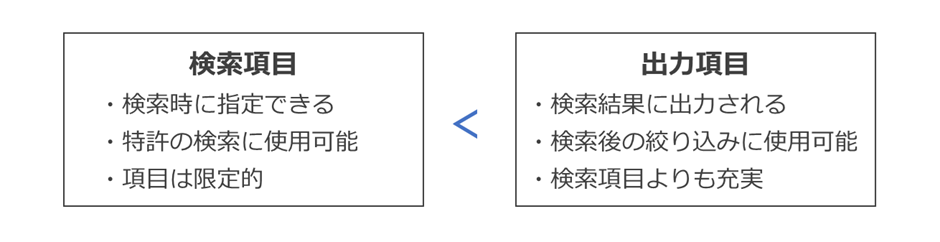
ただし、悩ましいのは、検索項目には限界があるという点です。
通常、特許データベースの検索項目は、検索結果の出力項目よりも少なくなっています。
たとえば、ある特許DBでは、検索結果の出願リストデータにおいて「拒絶理由条文コード」(各拒絶理由に対応する、特許庁が定めた条文コード)を出力することはできますが、「拒絶理由条文コード」で出願を検索することはできません。
つまり、「検索すればわかる情報」ではあるものの「その情報を使って検索をすることはできない」ということです。
例1:進歩性欠如に対して応答した事例
具体例として、進歩性欠如に対する応答パターンを調べたい場合を考えてみます。
この場合、理想的には「進歩性欠如が指摘された出願」を検索したいところです。
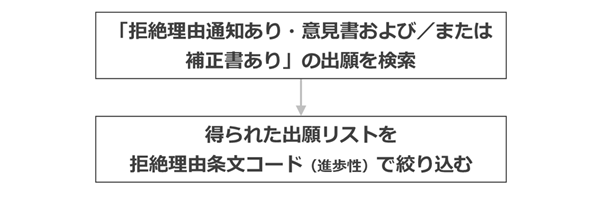
しかし、それができない特許DBであれば、たとえば、まず以下の条件を満たす出願を検索して、「拒絶理由通知に応答した出願リスト」を取得することになります(このような検索は、審査経過情報を検索できるDBであれば実行可能なことが多いです)。
- 拒絶理由通知が指摘され、かつ
- 意見書および/または補正書が提出された
その後、得られた出願リストを「拒絶理由条文コード」で絞り込んで、進歩性欠如が指摘されたもののみを抽出することになります。
例2:除くクレームを使って拒絶された事例
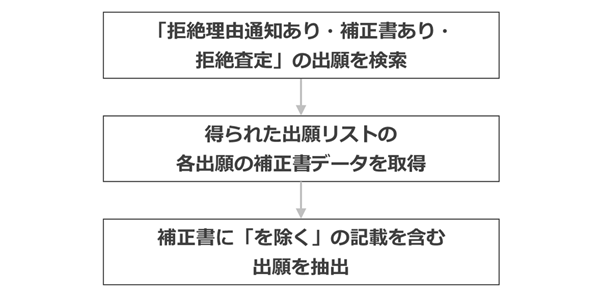
さらに難しい例として、除くクレームを使って拒絶された事例を研究対象にする場合を考えてみます。
もし特許事例であれば、特許公報を対象として、クレームが「を除く」という記載を含むものを検索すれば足ります。
しかし、拒絶事例はそうもいきません。除くクレームは通常、補正で導入されるからです。したがって、見たいのは公開公報や特許公報ではなく、補正書です。
ところが、筆者が調べた限りでは、現時点で、拒絶理由通知後の補正書の内容を検索できる商用DBはなさそうです。 このため、次のような流れになります。
かなり手間がかかりますが、こういうテーマではこのような回り道が必要になることが多いです。
なお、補正書データの取得は、特許庁APIを使えば可能です。
筆者が審査データを集めるときも、出願リストを入力すると、特許庁APIを介して各出願の審査書類データをダウンロードする自作のpythonプログラムを使っています。(pythonプログラムでは、特許情報簡易取得パッケージeasy_patentsに大いにお世話になりました。ありがとうございます!)
3.まとめ
今回は、体系的研究におけるデータの収集方法を、裁判例と審査事例とに分けて整理してみました。
なお、探索的研究など網羅性を要しない研究では、事例の探し方は上記とは全く異なるので、そちらについても機会があればまとめてみたいです。
次回は、データを集めた後の「分析」について書いてみようと思います。

田中 研二(弁理士)
専門分野:特許権利化(主に機械系、材料系)、訴訟