
こんにちは、知財実務情報Lab. 専門家チームの田中 研二(弁理士)です。
今回と次回は、前回紹介した「体系的研究」に着目して、最重要といっても過言ではない母集団の選び方について考えてみます。
母集団の選定は極めて奥が深く、到底私が軽々しく語れるテーマではないのですが、本記事ではあくまで「現実的な知財実務研究における考え方の一例」として、筆者なりに大事にしている点をご紹介します。
欧州(EPO)の特許実務は、日本と結構、違いますよね。
日本と同じ感覚で対応していると拒絶理由が解消されず、何回もOAが出て、権利化できたけど相当なコストがかかった、ということになりかねません。
そこで、日本の特許実務と、欧州の特許実務の違いを知っておく必要があります。
今回は、ドイツに在住し、欧州特許弁理士、ドイツ弁理士として活躍中、しかも日本の弁理士でもある長谷川先生に、日本との違いを意識した、欧州特許における権利化実務ポイントを解説して頂きます。
欧州特許の権利化実務に関係している方は、2026/2/20(金)にセミナーを開催しますので、ご参加ください。
詳細は以下をクリックして開くページからご確認ください。

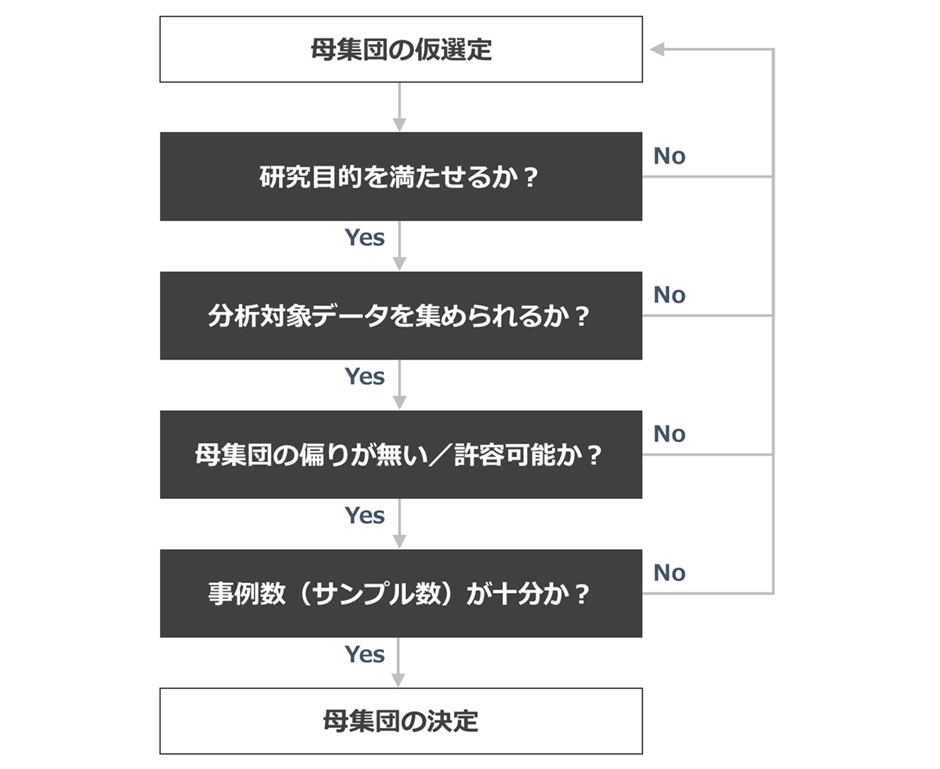
母集団を決めるときの4観点
私が個人研究や委員会活動などで体系的な研究を行う場合、母集団を選ぶときに意識しているのは、主に以下の4点です。
- 研究目的を満たせるか?
- 分析対象データを集められるか?
- 母集団の偏りが無い/許容可能か?
- 事例数(サンプル数)が十分か?
研究に使う母集団は、これらの4観点をすべて満たす必要があると考えています。
以下では、それぞれの観点について簡単に説明してみます。
観点(1):研究目的を満たせるか?
前回の記事で「目的」(何を知りたいか?)が一番大事と書いたとおり、知りたいことがわからない母集団はNGです。
・・・そりゃそうだ、と思われるでしょうが、データの集め方を考えているうちに「目的」の意識が落ちてしまうことは意外と少なくありません。
現実には、データの集めやすさから逆算して目的を修正することもあり得るものの、研究することが目的化してしまうのを防ぐためには、やはり何が知りたくて研究を始めたのかを常に意識することが大事です。
さて、「目的」を満たす母集団を選ぶには、目的から逆算することが有効です。
たとえば、前回の冒頭に挙げた「ネットワーク関連発明で有効なクレームドラフト手法を整理したい」という目的を考えてみましょう。
このテーマだと、まずは「有効とは何か?」を具体的に定義する必要があります。
「有効」=「侵害訴訟の充足論で強い」であれば、ネットワーク関連発明の侵害訴訟事件で充足・非充足の判断がされた裁判例を母集団として設定するのがよいかもしれません。
「有効」=「サブコンクレームにおける「他のサブコンビネーション」の限定が新規性・進歩性判断において無視されない」であれば、ネットワーク関連発明に係る特許出願のうちサブコンクレームを含むものを母集団として設定することが考えられます。
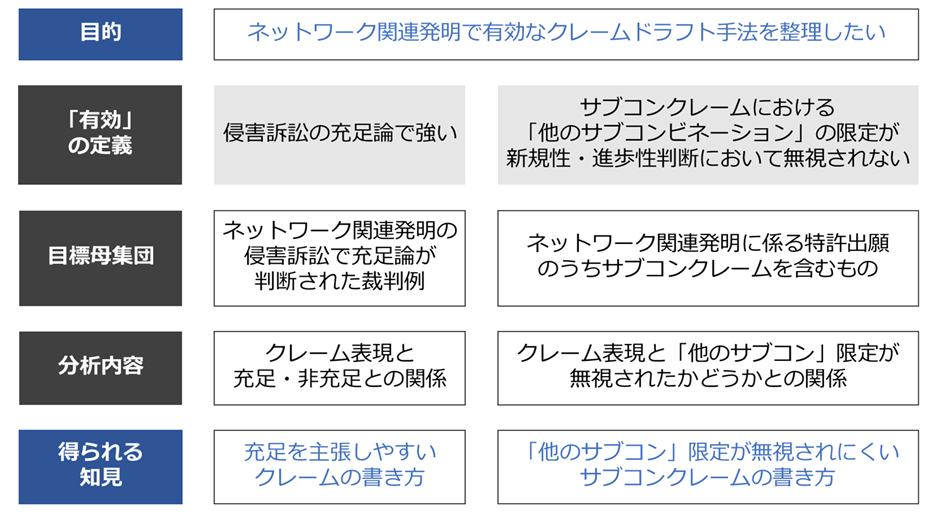
このように、分析から得られる知見がちゃんと「目的」の回答になるような母集団を選ぶことが必要です。
なお、母集団(「目標母集団」ともいいます)を考えるときは、まずはデータの集めやすさを考慮せず、目的に沿った知見が得られる「本当に見たい集合」を素直に定義します。具体的な事例データをどのように集めていくかは、観点(2)で考えます。
観点(2):分析対象データを集められるか?
2つめの観点は、分析対象のデータを集めることが可能かどうかです。
一般に、分析では、上記のように設定した目標母集団(=「本当に見たい集合」)に対して、それに属するサンプルを抽出するためのリスト(専門的には「標本抽出枠」や「サンプリングフレーム」などと呼びます)を作り、そこから分析対象を抽出します。

特許出願や裁判例のデータ自体は各種データベースで取得可能ですが、欲しい分析対象だけを狙って収集することはなかなか難しいことが多いです。
たとえば上記例では、「ネットワーク関連発明の侵害訴訟で充足論が判断された裁判例」は、裁判所Webサイトでキーワード検索により集めることが考えられますが、キーワード次第では含めるべき事例が漏れることもあり得ます。
漏れのない分析をしたいなら、日本の侵害訴訟の数は少ないので、ひとまず所定期間の裁判例全件をサンプリングフレームとして取得し、ここからスクリーニングによって分析対象を抽出することが考えられます。
一方、「ネットワーク関連発明に係る特許出願」であれば、特許分類を使ってある程度機械的に収集することはできるかもしれません。しかし、「サブコンクレームを含む特許出願」を特許データベースで検索することは難しそうですよね。
サブコンクレームを分析対象にしたいときは、「ネットワーク関連の特許分類が付与された特許出願」をサンプリングフレームとして取得し、そこからスクリーニングをして分析対象を抽出するしかなさそうです。
その後の分析としては、分析対象の各事例について「他のサブコンビネーション」の限定が無視されたかどうかをタグ付けし、審査で無視されにくいクレームの書き方を抽出していくことが考えられます。
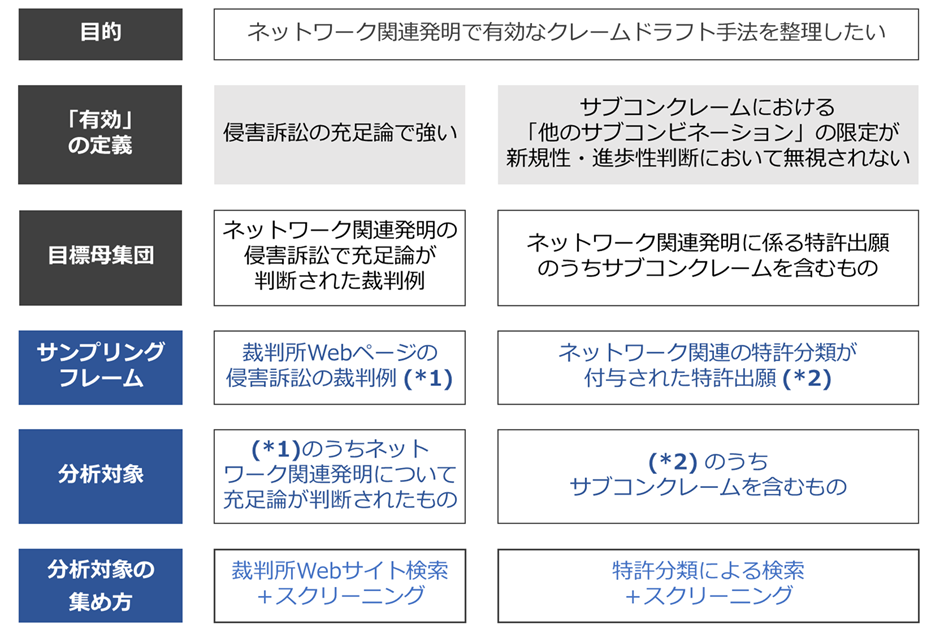
このように、まず各種データベースの検索によって、できるだけ母集団を代表または包含するサンプリングフレームを集め、その後はスクリーニングで分析対象を抽出する、という工程が一般的です。スクリーニングの難易度次第では、よりデータを集めやすいように母集団設定を見直すほうが効率的なこともあります。
ちなみに筆者の過去の研究では、「拒絶理由に対して補正をせずに反論した特許出願」(*)はほぼ機械的に抽出できましたが、「進歩性欠如に対して反論したもの」は機械的に抽出できなかったので、諦めて(*)の出願1件1件の拒絶理由通知を見て、進歩性欠如が指摘されたもののみに絞り込みました。
また、分析対象が目標母集団を適切に抽出できているか(代表性)も重要なチェックポイントです。知財研究では、特許庁や裁判所のデータベースが充実しているので、網羅的なサンプリングフレームの取得が比較的容易ですが、上記例では「ネットワーク関連の特許分類」によってネットワーク関連発明をちゃんと抽出できているか(漏れがないか/余計なものが大量に入っていないか)はしっかり確認する必要があります。
まとめ
ここまで説明してきた「目的との整合性」と「データ収集可能性」は、体系的研究を実施するための大前提となります。
最初はなかなか良い母集団を設定するのも難しいですが、試行錯誤を通じて少しずつ感覚が掴めてくるのではないかと思います。
だいぶ長くなってしまったので、より統計学的な観点である「母集団の偏り」と「サンプル数」については次回に回すことにします。

田中 研二(弁理士)
専門分野:特許権利化(主に機械系、材料系)、訴訟