
こんにちは、知財実務情報Lab. 専門家チームの田中 研二(弁理士)です。
今回は、前回に引き続き、「体系的研究」における母集団の取り方について考えてみます。
欧州(EPO)の特許実務は、日本と結構、違いますよね。
日本と同じ感覚で対応していると拒絶理由が解消されず、何回もOAが出て、権利化できたけど相当なコストがかかった、ということになりかねません。
そこで、日本の特許実務と、欧州の特許実務の違いを知っておく必要があります。
今回は、ドイツに在住し、欧州特許弁理士、ドイツ弁理士として活躍中、しかも日本の弁理士でもある長谷川先生に、日本との違いを意識した、欧州特許における権利化実務ポイントを解説して頂きます。
欧州特許の権利化実務に関係している方は、2026/2/20(金)にセミナーを開催しますので、ご参加ください。
詳細は以下をクリックして開くページからご確認ください。

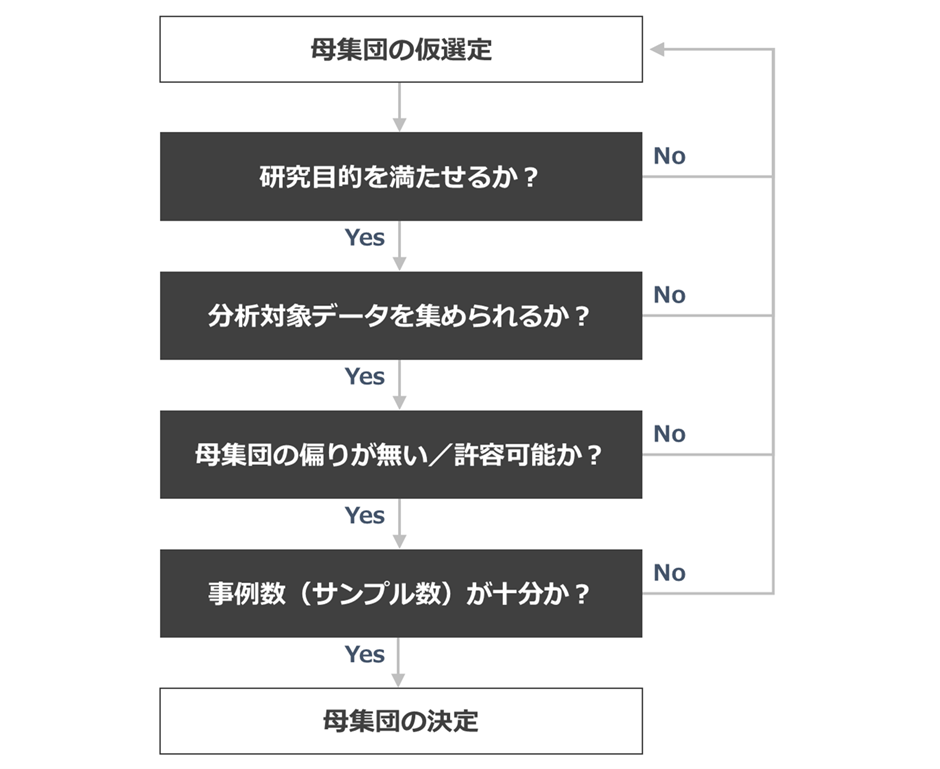
母集団を決めるときの4観点(再掲)
前回ご紹介したように、筆者が体系的研究における母集団の選定にあたって意識している4観点は以下のとおりです。
- 研究目的を満たせるか?
- 分析対象データを集められるか?
- 母集団の偏りが無い/許容可能か?
- 事例数(サンプル数)が十分か?
今回は、後半の2つの観点について紹介します。
観点(3):母集団の偏りが無い/許容可能か?
3つめの観点は、母集団自体の「偏り」です。
目標母集団を設定する際に、いわゆるセレクションバイアス(偏り)が入り込むことは少なくありません。
たとえば「ネットワーク関連発明の侵害訴訟事件の裁判例」は、侵害訴訟が提起され、かつ和解せず判決に至ったものに限られます。そうすると、侵害発見しにくいクレームや、当事者間で充足論の争いになりにくい権利範囲が明確なクレームは、そもそも分析対象から漏れている可能性が高いです。
また、サブコンクレームの例では、そもそも出願人が「サブコンで書くのが難しい」と考えてサブコンを採用しなかった出願は、分析対象に含まれません。
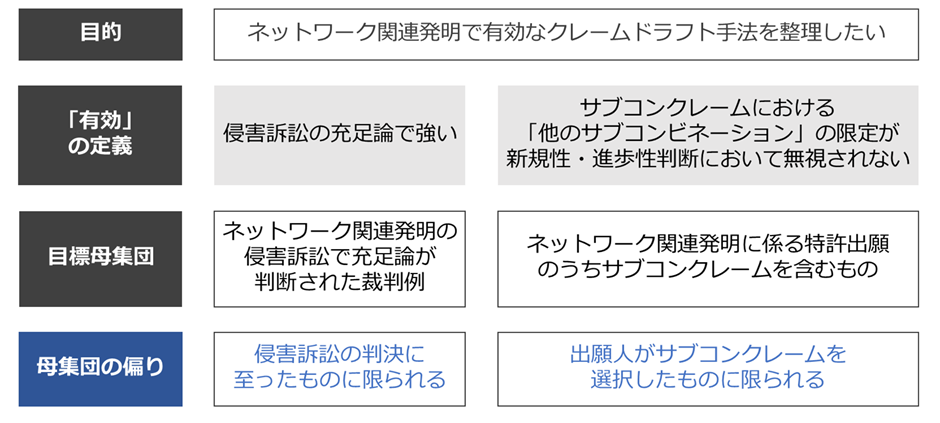
このように、母集団のセレクションバイアスを排除することは難しいことも多いので、分析結果は「そのバイアスがかかった集団について分析したもの」として提示するのが安全です。上記例では、「ネットワーク関連出願のうちサブコンクレームを含むものを対象として分析した」と明示し、対象を「あらゆるネットワーク関連出願」にまで一般化しないのがよいでしょう。
もちろん母集団の偏りが少ないに越したことはありませんが、完璧な統計データを作ることが目的でないのなら、実務研究としては、本来の「目的」に照らして有益な示唆が得られそうであれば、セレクションバイアスを前提として分析を進めてしまうのもアリだと思います。
以下、知財実務研究でよくあるセレクションバイアスを挙げておきます。
- 審査結果を母集団の条件に使う場合(例:特許事例だけを対象に選ぶと「失敗例」が漏れる。反論事例だけを対象に選ぶと「出願人が反論困難と判断した事例」が漏れる。審判事例だけを対象に選ぶと「出願人が審判を断念した事例」が漏れる)
- 未決事例を対象から除外する場合(例:審査結果が出ていない事例を除くと、審査が長引いている事例を取りこぼす)
- 出願日が一定期間内のもののみを対象とする場合(例:審査請求時期がばらつくので、分析結果が短期的な審査傾向の変化などに影響され得る)
ちなみに筆者の過去の研究でも、分析対象が「出願人が補正をせずに反論した特許出願」だったので、主に「出願人が反論できると判断した出願」と「補正しようがなく仕方なく反論した出願」で占められている可能性が高いです。
なお、前回の記事で観点(2)について注記したように、目標母集団の偏り(セレクションバイアス)とは別に、目標母集団と分析対象とのずれ(代表性の問題)にも注意しましょう。セレクションバイアスと代表性は混同しやすいですが、別物です。
観点(4):事例数(サンプル数)が十分か?
最後の観点は、統計的な精度です。
たとえば、ある反論を行った事例が4件あって、うち3件が特許、1件が拒絶されたからといって、「この反論の成功率は75%だから有効だ!」ということができないことは直感的にわかると思います。
成功率などの平均値を調べたいのであれば、「信頼区間」という考え方を使って、必要な事例数(サンプル数)を考えてみるとよいです。この辺りの話は、詳しい記事がたくさんあるので、興味のある方は一度そちらを見てみることをお勧めします(ざっくりいうと、誤差±10%程度で成功率を調べたいなら、サンプル数の目安は安全サイドで100件程度です)。
とはいえ、実務研究においてガチガチの統計的検証まで実施することは少ないです。現実的には、委員会などでの分析対象の事例数は100~500件くらいにすることが多いように思います。
ただし、細分化した分析を行いたい場合にはより多くの事例数が必要になることは注意しましょう。たとえば、全体が200件でも、技術分野別の傾向を見たくなったときに、事例数が10件しかない分野については、誤差が大きすぎて傾向を抽出することは難しいでしょう。この場合は、事例数の少ない分野については諦めるか、元の母集団のサイズをより大きくすることを検討することになります。
事例数の調整は、
- ランダム抽出(母集団が大きい場合)
- 期間の長さ(出願日、審査請求日、査定審決日、登録日など)
などにより行うことが多いと思います。
特許出願を対象とする研究では、母集団のサイズが数万件~数十万件になることもあるので、そこからランダムにサンプリングして分析可能な数に抑えたり、特定の期間に出願・審査請求・査定などがされたもののみ(たとえば、2025年に査定がされた出願のみ)を対象とすることがあります。
ただし、特定の期間に限定することによるセレクションバイアスも生じ得るので、それが研究目的に照らして許容可能かどうかは検証が必要です。
まとめ
前回から今回にかけて、体系的研究における母集団の選定について、私なりに意識している点をまとめてみました。
少し長くなってしまいましたが、このテーマは本当に奥が深く、考えれば考えるほど沼に沈んでいったりします。とりあえず仮に母集団を作ってデータを眺めてみて初めて、母集団設定のやり方が見えてくることも多いです。
一方で、最終的に「体系的研究」としてまとめるのであれば、必ず偏りや事例数の問題が浮上してくるので、母集団について試行錯誤する際には、上記の観点も頭に入れておくことをお勧めします。
次回は「データの集め方」について紹介してみようと思います。

田中 研二(弁理士)
専門分野:特許権利化(主に機械系、材料系)、訴訟